
The astonishing recent breakthroughs of Generative AI, in particular large language models such a Chat GPTs, have been stunning in the range of tasks which they can perform that superficially at any rate seem to require human insight. These applications appear unlimited, from generating poetry to writing computer code. But a recent study published by Massachusetts Institute of Technology (MIT) News infers that there is a critical limitation to this: even the best LLMs may lack a freighted sense of the world and its rules, leading to surprise failures on certain tasks. This is a key insight into the lack of assumptions built into how these models understand the world, implicit and solely from exposure to large datasets.
Researchers at MIT, Harvard, and Cornell are leading a team that has just published their findings in a study that tests whether popular LLMs powered by transformer-based architectures can form accurate “world models.” They focused much of their work on how well these AI systems can provide coherent representations of structured environments, say, navigating a city’s streets or playing a strategy game, where clear rules and spatial layouts apply. The results of the experiments show that while LLMs do well in a narrow scope of conditions, they easily break whenever there is a change in setting or even rules. These call for more executive ways of testing artificial intelligence.
The Illusion of Understanding
Transformers, which are the backbone of LLMs like GPT-4, are predictively good at patterns in sequential language-based data. This prowess can give an appearance that they are internalizing world models-or even broader truths-as evidenced now and then, for instance, by their surprising capability to output valid directions in a city like New York or predict valid moves in complex games like Connect 4. The researchers stress, however, that such abilities could be misleading. The study shows that LLMs can achieve high performance without forming genuine internal representations of their environment.
In one test, the AI gave perfect directions, turn by turn, through New York City. But then, with a small perturbation-say, closing certain streets or adding detours-the model utterly fell apart. This points to a serious failing: the model didn’t build a true spatial map of New York. Instead, it had created an imaginary version of the city that includes streets that do not exist and illogical connections between streets, indicative of how much LLMs depend on their probability-based predictions rather than on spatial or logical understanding.
Introducing New Evaluation Metrics
With such a motive to test the structured environments, how well is the understanding done by LLMs, the research team introduced two newer metrics, namely, sequence distinction and sequence compression. These metrics are inspired by the concept of deterministic finite automations, or sequences of states according to rules-like moving around city streets or declaring legal moves using a game of Othello. Sequence Distinction is a measure of how well a model can tell the difference between two distinct states. For example, this may mean telling the difference between two Othello boards or between two different intersections on a city map. It’s a metric that checks whether the model can learn distinct representations for different scenes. Sequence Compression checks if the model is able to recognize identical states and knows that they allow for the same subsequent actions. Consider two identical Othello boards that present the same moves; such should be distinguished by a model having a coherent world model. These metrics go beyond the conventional performance metrics to tell whether an LLM has learned the rules of an environment, or it has simply learned to predict the outcomes based on its past experiences.
Findings – Incoherent World Models in AI
The results of this study put forward a very realistic situation. Although LLMs, including transformer-based models, may generate appropriate directions or legally correct game plays, this doesn’t count as meaningful comprehension of the world. For one thing, transformers that are still trained on randomly generated sequences-e.g., a heuristic mix of moves in Othello-appeared to develop superior world models than those strictly trained on strategically sound sequences. This is likely because the random sequences expose the model to a wider set of possibilities, including “bad” moves that skilled players might avoid, and help widen its scope of possible actions. When the researchers introduced changes-say, detours in the layout of New York-all navigation models failed. Models did not adapt well to the change in the environment and maps they created featured fantastic streets and links with no relation to reality. The presence of these “phantom” features has shown that the AI was producing output based on patterns, rather than from any meaningful understanding of space, and apparent accuracy under original conditions masked actual lack of real comprehension.
Implications for the deployment of generative AI into real-world applications are great. If seemingly precise and reliable AI models collapse under minor changes in the environment, they can become a hazard when applied in domains that require high adaptability and context understanding-for instance, autonomous driving, health diagnostics, and complex decision-making. This can lead to several dangerous errors in those fields where random variables pop up regularly. A self-driving car, while executing only instructions generated by LLMs without a strong sense of spatial knowledge, may get lost with detours or at sudden road closures. In healthcare-related applications, if an AI model is supposed to generate diagnoses or suggest treatment, it may perform well in artificially controlled environments but may completely fail at unusual symptoms or non-standard patient histories thrown in such systems.
The Way Forward: A Call for Caution and Further Research
According to Ashesh Rambachan, the senior author of the study, these findings call for caution in assessing the capabilities of AI in complex domains. According to Rambachan, while thecao LLMs have outstanding proficiency in language, the translation of these abilities into other scientific and practical areas begs more stringent evaluation. These authors appeal for novel techniques in training AI that go beyond the objective of predictive accuracy. If models are ever to gain deep insight, they must be trained in world modeling competencies, coherent and well beyond theMost successes posted by deep learning approaches rely heavily on associations that can be captured using a statistics-based approach. That means conditioning AI on more varied and diverse scenarios-and possibly creating hybrid models leveraging a greater degree of rule-based or symbolic reasoning to complement data-driven learning.
Conclusion: Putting AI’s Limitations and its Potential in Perspective
The recent findings on generative AI’s limitations give a reason to alter the understanding of its capabilities. Large language models can give an impression of understanding by producing normal-sounding responses in well-bounded contexts but can fall apart with even slight changes in wording, which gives away that they lack robust models of the world. And that is important to keep in mind as AI continues to evolve and is deployed across multiple sectors. Backed by key organizations, such as the National Science Foundation and the MacArthur Foundation, this study pinpoints a specific focus for the direction of future studies: to develop AI systems that are not just performing well but even understand the environments in which they’re operating. Before AI could really help solve complex problems, we have to understand its gaps and address them so these high-powered tools can serve effectively and safely in real-world applications.
Dr. Prahlada N.B
MBBS (JJMMC), MS (PGIMER, Chandigarh).
MBA (BITS, Pilani), MHA,
Executive Programme in Strategic Management (IIM, Lucknow)
Senior Management Programme in Healthcare Management (IIM, Kozhikode)
Postgraduate Certificate in Technology Leadership and Innovation (MIT, USA)
Advanced Certificate in AI for Digital Health and Imaging Program (IISc, Bengaluru).
Senior Professor and former Head,
Department of ENT-Head & Neck Surgery, Skull Base Surgery, Cochlear Implant Surgery.
Basaveshwara Medical College & Hospital, Chitradurga, Karnataka, India.
My Vision: I don’t want to be a genius. I want to be a person with a bundle of experience.
My Mission: Help others achieve their life’s objectives in my presence or absence!
My Values: Creating value for others.
Leave a reply














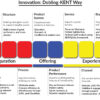
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
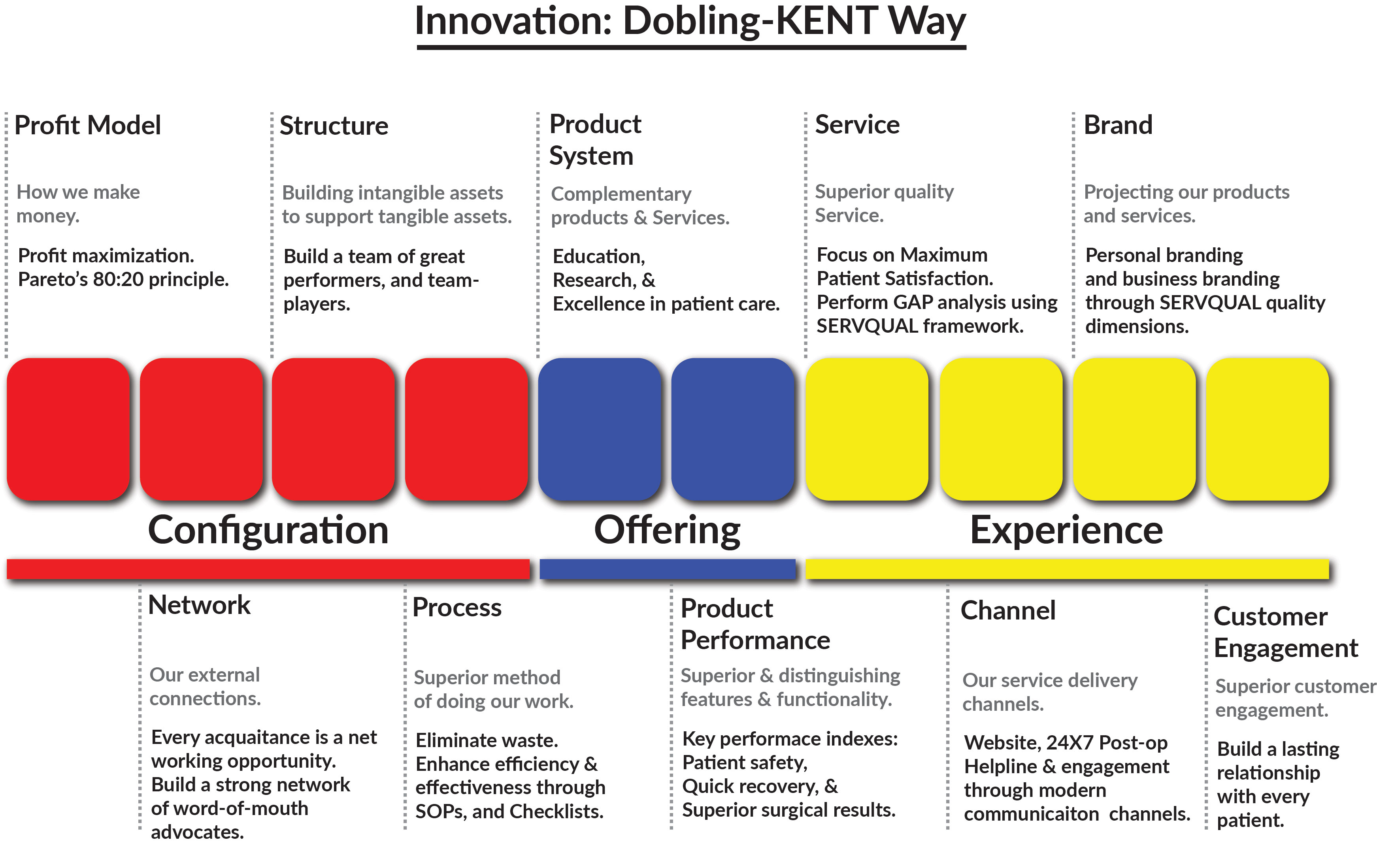{kind=link}
*Prahlada Sir 💐*,
Your nice blog article, can be written in a shorter format as below :
*The Power and Pitfalls of Large Language Models*
Generative AI and ChatGPT have revolutionized human-computer interaction, but their limitations hinder true understanding. Trained on patterns, not underlying logic, these models struggle to grasp real-world rules.
*The Knowledge Gap*
Imagine learning a language from books alone, without conversing with natives. You'd recognize phrases, but miss nuances and context.
*Limitations of Large Language Models*
1. Lack of common sense
2. Overfitting
3. Double descent
*The Pursuit of Progress*
Researchers explore:
1. Simpler models
2. Alternative training methods
3. Hybrid approaches
*Key Insights*
– Large language models lack real-world experience
– Researchers seek improved robustness and generalizability
– Hybrid approaches show promise
*Future Horizons*
– Combining AI techniques
– Developing interpretable models
– Advancing training methods
*Conclusion*
While Generative AI and ChatGPT have made strides, there's still much to discover. By acknowledging limitations and exploring new approaches, we can craft more intelligent, robust, and helpful AI systems.
Reply